Annotating videos
Creating high-quality training data from a video datasets
When a model trained on image data encounters two separate images, it has no way of knowing how the two are related. For example, a model may be able to recognize a type of organism in a series of images taken by a microscope, but it may not understand that each image shows the same organism in a different position or at a different time. If your use case requires your algorithm to identify and track objects over time — such as the movement of an organism or various situations encountered on the road by a vehicle — you will likely get better results by training your model with video data.
Video data is often annotated similarly to image data: with bounding boxes and segmentation masks. In addition to tracking objects over time, these algorithms can be “taught” to develop object permanence, as an object that appears in one frame may be out of frame or occluded in another, and the model needs to understand that it still exists. Well-labeled video data can help models measure the speed and velocity of objects, track patterns in movement, size, distance, and more.
Labeling video data
The process of labeling video data can often be much more arduous — and as a result, more expensive — than labeling images. Labelers might need to annotate hundreds of frames to label a single video. While a training data platform makes it easier and more efficient for teams labeling images to produce high-quality training data, it is a necessity for teams who need to label videos. They require a platform that not only optimizes the process with queueing and a centralized space for producing training data; they also need essential tools that make labeling video data easier.
Multitrack timeline
Video annotation is most successful with a labeling editor that lets users see all their annotations, jump from frame to frame easily, and track each object’s appearance within the timeline of the video.
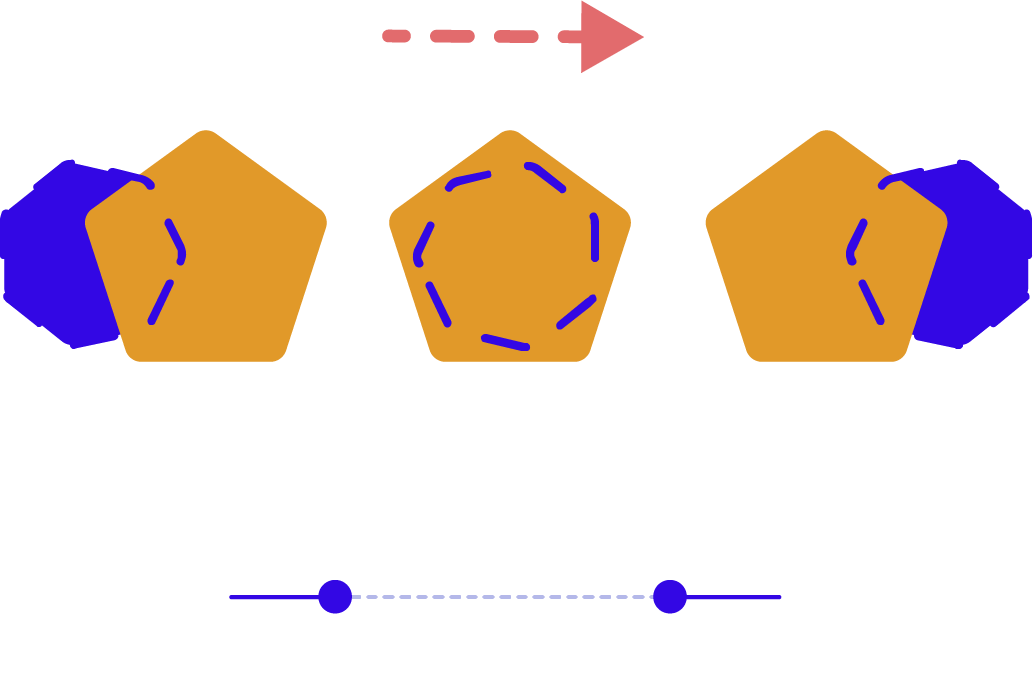
Linear interpolation
Labeling each and every object in every frame of a video can quickly become a chore. A labeling tool that uses linear interpolation to move annotations through frames once the labeler creates them at the beginning and end of a video or video segment can save hours of time.
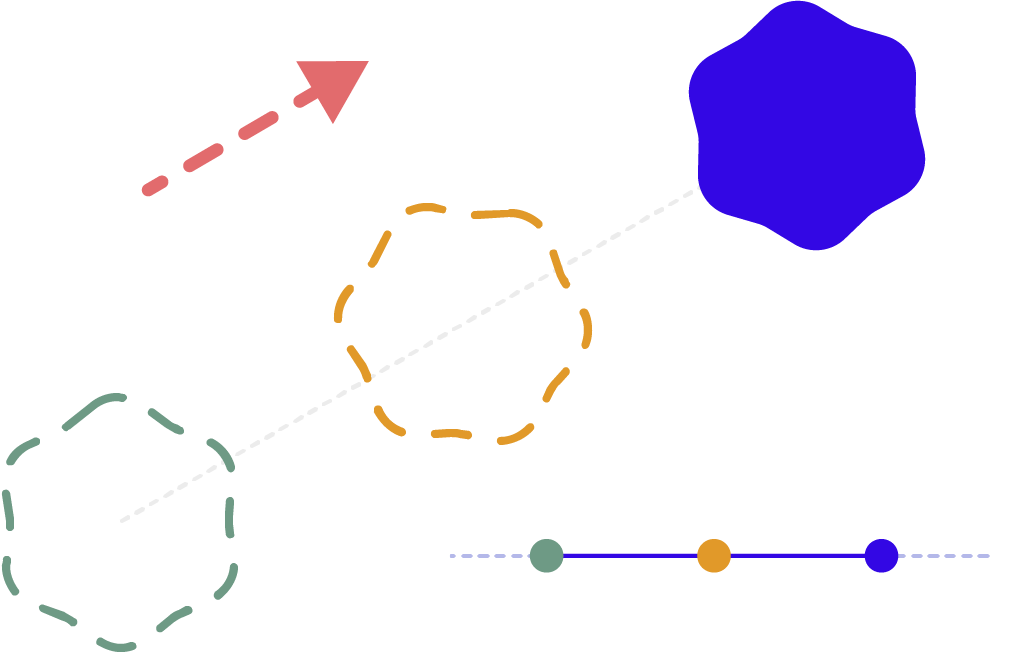
Smart IDs
If a labeled object is occluded or out of sight for part of the video, labelers will need to track it frame by frame and ensure that the same label is added in the exact frame where it reappears. An editor with a smart ID system can take this work off the labelers’ plate by automatically assigning the right label even when objects have been out of view.