Training data platforms
The key to creating high-quality training data for machine learning
AI teams today face a serious gap in tooling. Building models requires software that enables teams to create and manage high-quality training data. Too often, they end up building these tools in house, and these solutions often require maintenance, lack intuitive workflows, and hinder growth.
A training data platform (TDP) can not only mitigate these challenges, but also provide additional features that help AI teams build the ideal data engine for their use cases, such as queueing, built-in collaboration tools, and more. TDPs empower AI teams with powerful, configurable labeling editors for a variety of data types, a single source of truth for the whole organization’s training data, and complex workflows that support quality management, iteration, automation, active learning, and more.
Teams that use TDPs produce higher quality training data at a fast and cost-efficient pace. They can also develop a more nuanced understanding of model performance during and after the training process, and curate training datasets accordingly to ensure significant leaps in performance. This process can help AI teams get their models to production-ready performance faster than ever before.
Creating high-quality training data presents several challenges to machine learning teams
With all these challenges and more, machine learning teams spend the bulk of their time on building tools and processes to create training data, rather than actually training models.
Secure data transfers
Ontology setup
Keeping track of data
Quality management
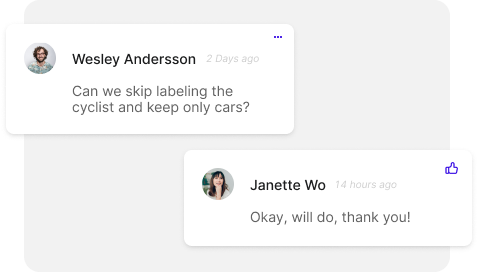
Collaborating between labelers and stakeholders

New annotation tools for every use case
A training data platform enables machine learning teams to efficiently create high-quality training data.
A training data platform enables machine learning teams to set up their labeling workflow, produce high-quality training data, and train their models quickly and efficiently.
Integrated collaboration

Real-time queueing

Built-in dashboards to track quality and production
Multiple, flexible labeling interfaces
Easily integrated quality management workflows
Support for multiple data types
Tools for high quality training data by data type
Learn about the specific requirements your labeling tools will need to have to help your ML team produce high-quality training data for computer vision, text, and audio use cases.
Images
Video
Text
Audio
Images
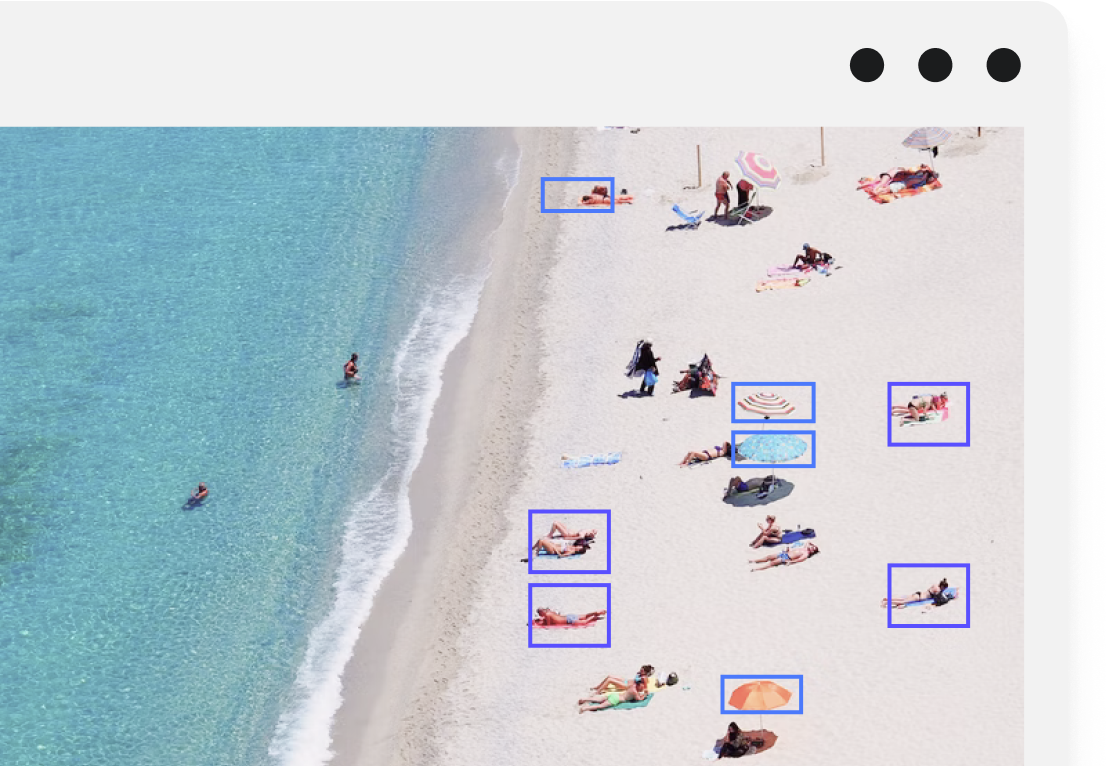
Computer vision projects that require image data are one of the most common types of machine learning use cases. Typically, ML teams have large, unstructured datasets that they need to organize and label before they can be used to train a model. To do this, teams will need flexible, configurable tooling that lets them label each image according to specifications for their use case.
Learn moreVideo
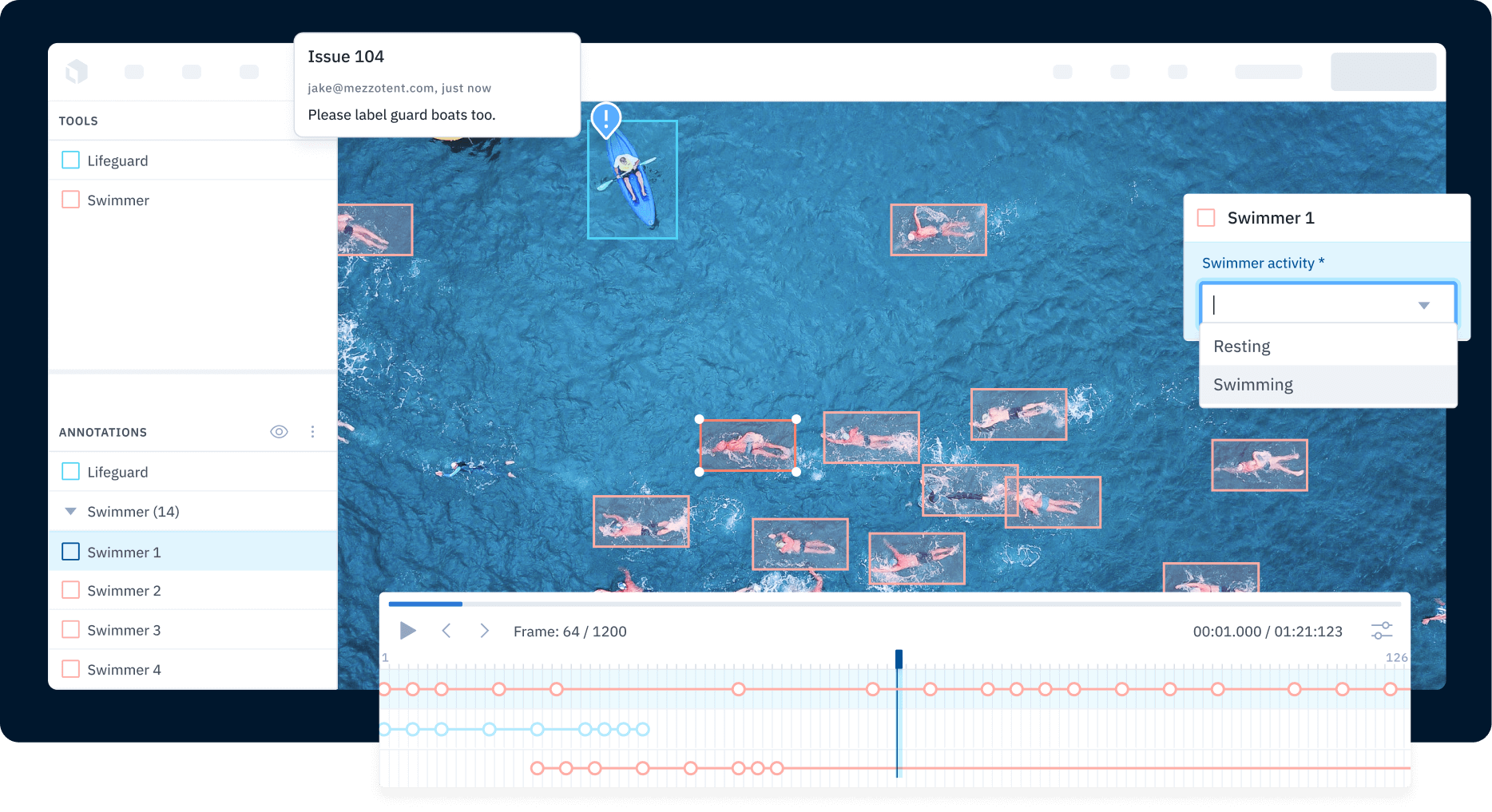
This type of computer vision project presents more complexity than an image-based use case. Most video ML projects require the model to track an object throughout the video. This requires the model to have a basic understanding of temporality — that an object in one frame is the same object in a different frame even though their locations are different. This will require an editor created specifically to label video data.
Learn moreText
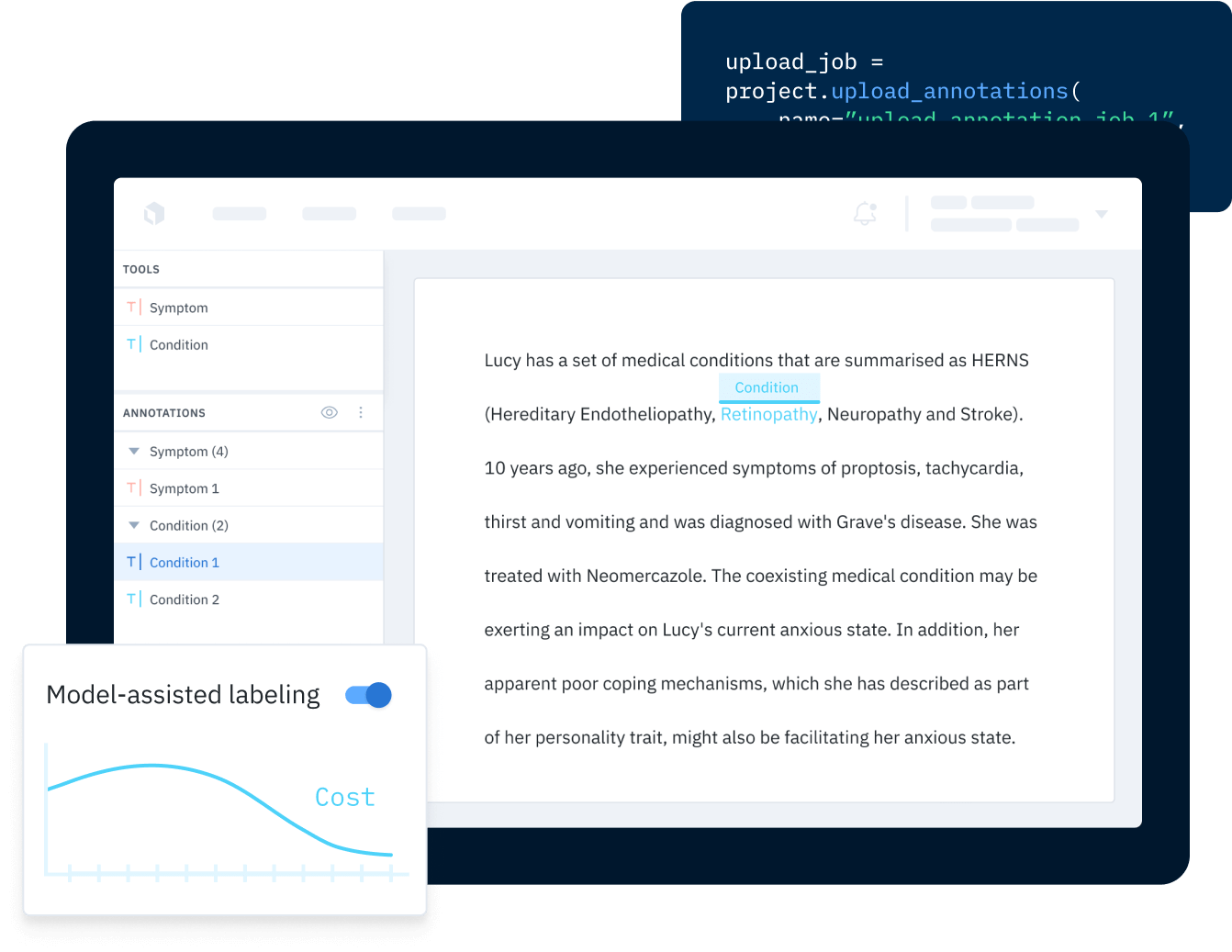
ML projects based on text data present yet another set of challenges. The labeling tool for these use cases need to be flexible for multiple languages, including those read from left to right and right to left. It will also need to allow labelers to label words, parts of words, sentences, punctuation, and more — an entirely different set of labels from the segmentation masks and bounding boxes often used to label images and videos.
Audio
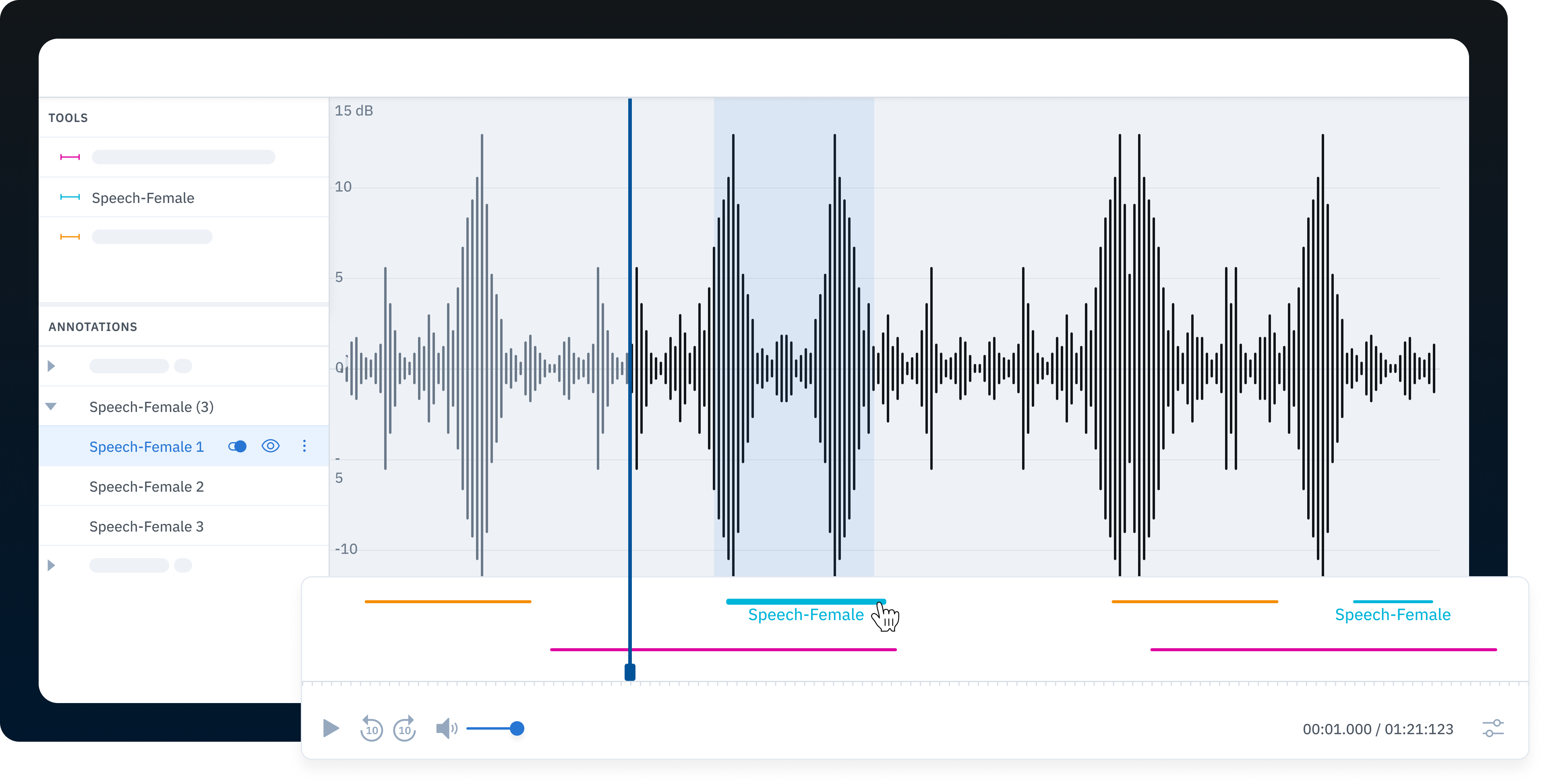
For some audio ML projects, teams can transcribe audio into text and simply label the transcription in a text editor. For use cases that require a model to identify distinct sounds and voices, however, teams will require a labeling tool created specifically for processing and labeling audio files and enable labelers to apply global labels for audio quality or language, as well as timestamp labels to identify specific speakers, instruments, etc.